



Modele językowe dużej skali (LLM), takie jak GPT-4 czy Gemini, zrewolucjonizowały nasze interakcje z technologią, oferując bezprecedensowe możliwości w przetwarzaniu języka naturalnego. Jednak ich wiedza ma granice – obejmuje tylko dane dostępne w momencie treningu. Oznacza to, że nie rozumieją one najnowszych wydarzeń, ale przede wszystkim nie znają prywatnych danych twojej firmy: dokumentów, raportów, faktur, procedur czy umów. W praktyce to właśnie te informacje są najcenniejsze w procesach decyzyjnych.
Rozwiązaniem jest Retrieval-Augmented Generation (RAG) – podejście, które uzupełnia i wzmacnia możliwości LLM. RAG ogranicza także problem tzw. halucynacji (pozornie wiarygodnych, ale fałszywych odpowiedzi). Dzięki integracji z zewnętrznymi i wewnętrznymi źródłami danych, system RAG pozwala generować odpowiedzi zakorzenione w aktualnych, kontekstowych i bezpiecznych informacjach firmowych.
Ta synergia przełamuje ograniczenia czysto generatywnych modeli i otwiera drogę do bardziej wiarygodnych interakcji AI – zarówno w obsłudze klienta, jak i w pracy analityków czy menedżerów.
Retrieval-Augmented Generation sprawia, że LLM stają się nie tylko sprytnymi generatorami treści, ale też aktywnym interfejsem do bazy wiedzy organizacji, działającym w oparciu o dokumenty w dowolnym języku.
TL;DR
- RAG wzmacnia LLM-y integracją z zewnętrznymi i firmowymi danymi, co daje trafniejsze odpowiedzi i eliminuje problem halucynacji.
- Typowy system RAG składa się z modułu wyszukiwania, modułu augmentacji i modułu generowania odpowiedzi – w efekcie przekształca dokumenty w użyteczną wiedzę, wspierając procesy decyzyjne.
- Dane kontekstowe obejmują często prywatne zasoby firmowe, których modele językowe same nie znają – RAG umożliwia ich bezpieczne wykorzystanie.
- Najnowsze wdrożenia korzystają z nowoczesnych baz wektorowych (np. pgvector w PostgreSQL, LanceDB) oraz wbudowanych mechanizmów monitoringu jakości odpowiedzi.
- RAG ma zastosowania od QA i wyszukiwania kontekstowego, po fact-checking, controlling czy onboarding nowych pracowników.
- Zbudowanie PoC jest łatwe, ale produkcyjne wdrożenie wymaga architektury i bezpieczeństwa klasy enterprise.
- Recordya to gotowy system RAG po polsku, który działa z plikami w różnych językach i jest dostępny od ręki dla twojej firmy.
Dekodowanie Retrieval-Augmented Generation (RAG)
Nowoczesne modele językowe uczą się na ogromnych zbiorach danych, gromadząc szeroką wiedzę w tzw. pamięci parametrycznej (wagi sieci neuronowych). Jednak same z siebie nie mają dostępu do aktualnych ani wewnętrznych danych organizacji. To prowadzi do nieścisłości albo niepełnych odpowiedzi, zwłaszcza w obszarach wymagających specjalistycznej wiedzy.
Tradycyjne podejście, czyli fine-tuning modelu na prywatnych danych, jest kosztowne, czasochłonne i mało elastyczne. Dlatego coraz częściej stosuje się Retrieval-Augmented Generation – zaproponowane w 2020 roku przez Facebook AI Research, UCL i NYU.
RAG łączy model generatywny z modułem wyszukiwania, pozwalając systemowi dynamicznie sięgać po istotne dokumenty firmowe i aktualne dane zewnętrzne. W efekcie odpowiedzi stają się bardziej precyzyjne, a retraining przestaje być koniecznością.
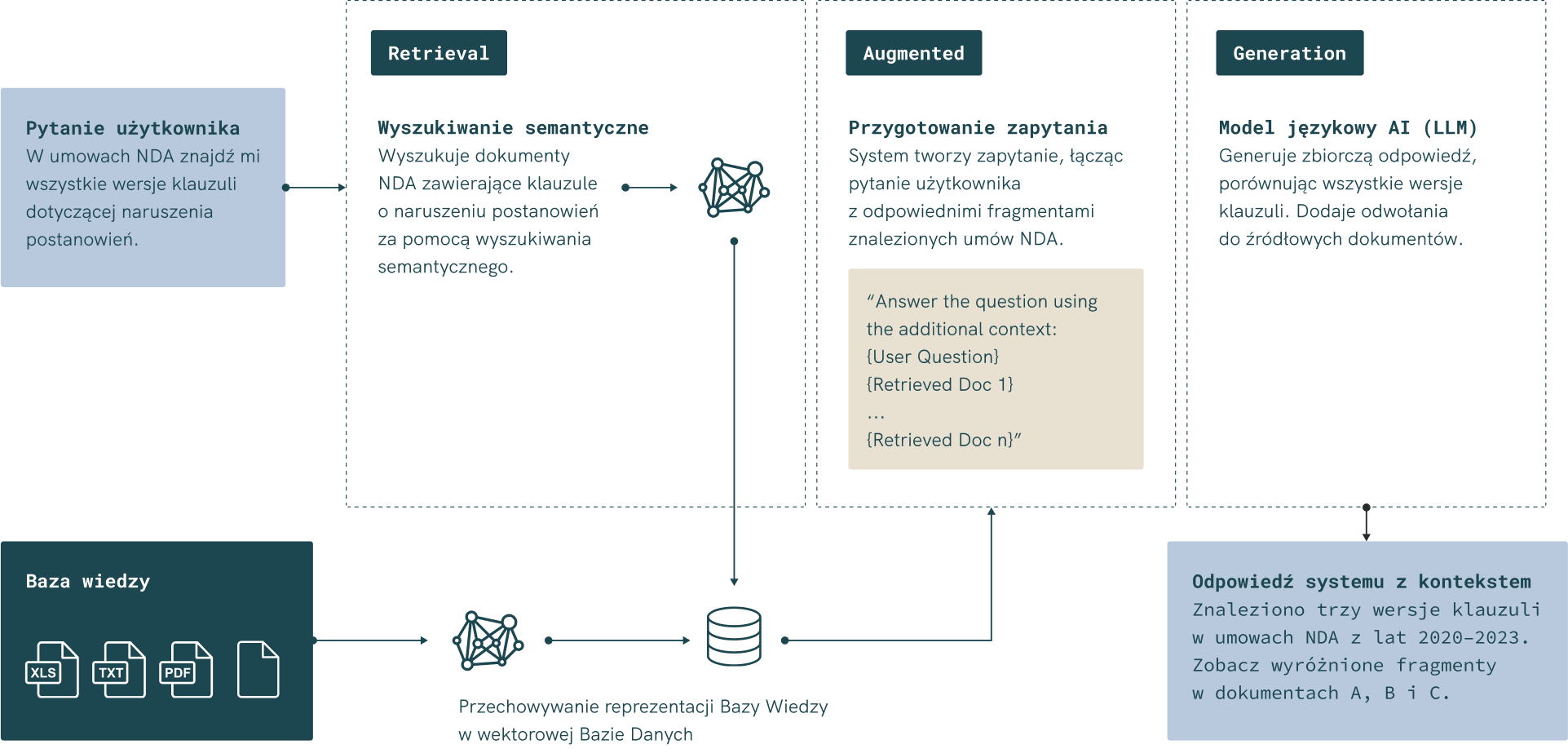
Główne komponenty RAG:
- Retrieval (wyszukiwanie): pobiera odpowiedni kontekst z bazy dokumentów.
- Augmentation (augmentacja): łączy zapytanie użytkownika i kontekst w prompt.
- Answer generation (generowanie odpowiedzi): LLM tworzy wynik zakorzeniony w danych organizacji.
Dzięki temu RAG umożliwia nie tylko dostęp do wiedzy publicznej, ale przede wszystkim do najważniejszych zasobów przedsiębiorstwa – tych, które stanowią o jego przewadze konkurencyjnej.
Rola danych kontekstowych i przetwarzanie dokumentów w RAG
W systemach Retrieval-Augmented Generation dane kontekstowe pełnią kluczową rolę – to one rozszerzają możliwości modeli językowych i pozwalają na wykorzystanie ich w realnych procesach biznesowych.
Dlaczego dane zewnętrzne i wewnętrzne są tak ważne?
Modele językowe same z siebie nie znają prywatnych zasobów firmowych:
- dokumentów finansowych i controllingowych,
- raportów badawczych i technicznych,
- umów, regulaminów czy klauzul prawnych,
- procedur wewnętrznych i wiedzy eksperckiej pracowników.
To właśnie te informacje są fundamentem procesów decyzyjnych w przedsiębiorstwie i budują kapitał intelektualny organizacji. Bez dostępu do nich AI nie jest w stanie dostarczać odpowiednich informacji wspierających realne decyzje menedżerów czy zespołów operacyjnych.
RAG pozwala wypełnić tę lukę, ponieważ łączy:
- wiedzę parametryczną (utrwaloną w modelu w trakcie treningu),
- wiedzę nieparametryczną (przechowywaną w bazach danych – np. wektorowych repozytoriach tworzonych z dokumentów firmowych).
Dzięki temu możliwe jest analizowanie i generowanie odpowiedzi w oparciu o aktualne, wewnętrzne i bezpieczne dane – bez konieczności udostępniania ich dostawcom modeli językowych.
Jakie daje to korzyści?
- Dostęp do aktualnych informacji – RAG umożliwia włączenie do procesu analizy najnowszych plików, raportów i procedur, bez kosztownego retrainingu.
- Bezpieczeństwo i kontrola – dane pozostają w obrębie organizacji (np. przy wdrożeniach lokalnych on-premise), co gwarantuje zgodność z regulacjami.
- Budowanie przewagi konkurencyjnej – firma korzysta ze swojego unikalnego know-how, które staje się dostępne dla pracowników w formie natychmiastowych odpowiedzi.
- Kontekst wielojęzyczny – Recordya pozwala na pracę z dokumentami w różnych językach (np. polski, angielski, hiszpański), co odzwierciedla realne potrzeby globalnych zespołów.
Dlaczego to zmienia grę?
W praktyce oznacza to, że RAG staje się bazą wiedzy nowej generacji – nie ogranicza się do tego, co wiedziała AI w momencie treningu, ale korzysta z tego, co naprawdę istnieje w twojej firmie tu i teraz.
To podejście fundamentalnie zmienia sposób zarządzania wiedzą i procesami decyzyjnymi:
- informacje są zawsze aktualne,
- pracownicy mają dostęp do kontekstu bez żmudnego wyszukiwania,
- a wiedza nie znika przy rotacji pracowników, tylko zostaje w organizacji.
Mechanika działania systemu RAG
Systemy RAG to połączenie mocy generowania języka przez LLM-y z precyzją wyszukiwania kontekstowego w dokumentach. Dzięki temu mogą one odpowiadać na pytania użytkowników nie tylko na podstawie ogólnej wiedzy, lecz także w oparciu o prywatne zasoby firmy.
Główne fazy działania systemu RAG
- Ładowanie dokumentów i dzielenie treści na fragmenty
- Dokumenty z różnych źródeł (np. PDF-y, raporty, faktury, notatki, bazy danych) są wczytywane do systemu.
- Tekst dzielony jest na mniejsze fragmenty (tzw. chunki), co pozwala na szybkie wyszukiwanie i analizowanie istotnych informacji.
- Przekształcanie tekstu w wektory (embeddingi)
- Fragmenty dokumentów są zamieniane na reprezentacje numeryczne (wektory) przez modele embeddingowe.
- Dzięki temu komputer może analizować zależności semantyczne między zapytaniem użytkownika a treściami w bazie wiedzy.
- Wyszukiwanie w bazie wektorowej
- Recordya korzysta z nowoczesnych technologii baz danych, takich jak pgvector (PostgreSQL) czy LanceDB, które pozwalają na szybkie wyszukiwanie najtrafniejszych fragmentów.
- Wyszukiwanie odbywa się nie tylko po słowach kluczowych, ale także po znaczeniu treści, co eliminuje problem dopasowania „po powierzchni” i zwiększa dokładność odpowiedzi.
- Augmentacja zapytania
- Zapytanie użytkownika zostaje wzbogacone o kontekst wyszukany w bazie dokumentów.
- Tworzony jest prompt z danymi firmowymi, który trafia do modelu językowego.
- Generowanie odpowiedzi
- LLM, korzystając zarówno ze swojej wiedzy ogólnej, jak i z dostarczonych fragmentów dokumentów, tworzy odpowiedź.
- Dzięki temu użytkownik otrzymuje natychmiastową, rzetelną i kontekstową informację, opartą na realnych danych firmy.
.png)
Różne strategie odpowiedzi
W zależności od złożoności pytania i ilości dokumentów, system RAG może używać różnych metod:
- Stuffing – proste wstrzyknięcie kontekstu do promptu (najlepsze dla krótkich zapytań).
- Map-Reduce – dzielenie dużych dokumentów na fragmenty, generowanie częściowych odpowiedzi i łączenie ich w całość.
- Refine – iteracyjne uzupełnianie i poprawianie odpowiedzi.
- Map-Rerank – ocenianie trafności wielu fragmentów i wybieranie najlepszych.
Dzięki tym technikom RAG jest w stanie obsługiwać zarówno szybkie pytania operacyjne („Który kontrakt wygasa w tym kwartale?”), jak i złożone analizy strategiczne.
Dlaczego to działa?
To podejście pozwala pracownikom szybko dotrzeć do właściwych danych, bez konieczności samodzielnego przeszukiwania dziesiątek dokumentów. W efekcie system staje się bazą wiedzy, która wspiera procesy decyzyjne, usprawnia przekazywanie wiedzy nowym pracownikom i automatyzuje przetwarzanie dokumentów w organizacji.
Wpływ RAG na przetwarzanie języka naturalnego i zarządzanie wiedzą
RAG fundamentalnie zmienia sposób, w jaki organizacje korzystają z informacji. To już nie tylko generowanie treści, ale przede wszystkim budowanie bazy wiedzy, która wspiera procesy decyzyjne w przedsiębiorstwie i pozwala na realne wykorzystanie kapitału intelektualnego firmy.
RAG po polsku – dlaczego to wyjątkowe wyzwanie?
Analiza języka polskiego stawia przed systemami AI dodatkowe bariery. Nasz język jest fleksyjny, bogaty w odmiany i dopuszcza zmienny szyk zdania. Oznacza to, że:
- proste metody chunkingu mogą gubić istotne informacje,
- tradycyjne podejścia oparte tylko na słowach kluczowych nie radzą sobie z pełnym znaczeniem treści,
- duże modele językowe, trenowane głównie na języku angielskim, mają ograniczoną znajomość polskiej semantyki i formalnych stylów (np. języka prawniczego czy technicznego).
Dlatego RAG po polsku to nie jest tylko tłumaczenie technologii, ale jej realne dostosowanie do specyfiki języka.
Recordya rozwiązuje ten problem, bo:
- stosuje mechanizmy wyszukiwania kontekstowego zamiast samego dopasowania słów kluczowych,
- lepiej radzi sobie z dokumentami prawnymi, finansowymi i technicznymi,
- działa wielojęzycznie (PL/EN/ES), ale jest przede wszystkim gotowym systemem RAG po polsku dla twojej firmy.
Przewaga RAG w procesach decyzyjnych
Dzięki temu podejściu pracownikom łatwiej znaleźć odpowiednie informacje, nawet jeśli formułują zapytania użytkowników w różny sposób. W praktyce oznacza to:
- natychmiastowe odpowiedzi na pytania w oparciu o aktualne dokumenty,
- realne wsparcie procesów decyzyjnych menedżerów i analityków,
- możliwość analizowania i generowania treści z wykorzystaniem prywatnych zasobów firmy,
- przewagę konkurencyjną nad organizacjami, które polegają tylko na ogólnej wiedzy modeli językowych.
Główne zastosowania RAG
- QA (Question Answering) – odpowiedzi na pytania użytkowników wprost z dokumentów organizacji.
- Wyszukiwanie kontekstowe – zamiast dopasowania słów kluczowych, system korzysta z semantyki i zależności w tekście.
- Streszczanie i wyodrębnianie treści – menedżerowie dostają skróty raportów z wyróżnieniem najważniejszych danych.
- Onboarding nowych pracowników – szybsze przekazywanie wiedzy i socjalizacja w kulturze organizacyjnej firmy.
- Controlling i finanse – automatyzacja przetwarzania dokumentów: faktur, raportów, zestawień.
- Obsługa klienta – baza wiedzy dostępna dla konsultantów i klientów w dowolnym miejscu i czasie.
Dlaczego to ważne dla twojej firmy?
RAG to nie tylko technologia, ale podejście do zarządzania wiedzą. Dzięki niemu twoje przedsiębiorstwo może:
- wykorzystać własne zasoby dokumentowe w oparciu o AI,
- ograniczyć konieczność ręcznego przeszukiwania dokumentów,
- wspierać pracowników w podejmowaniu decyzji,
- rozwijać strategię zarządzania wiedzą, która daje trwałą przewagę konkurencyjną.
Zastosowania RAG
Choć teoria jest istotna, prawdziwa wartość RAG ujawnia się dopiero w praktyce. Wdrażając RAG po polsku, firmy mogą zmienić sposób zarządzania wiedzą, przetwarzania dokumentów i wspierania procesów decyzyjnych.
1. Obsługa zapytań użytkowników
W firmach codziennie pojawiają się pytania: „Który kontrakt wygasa w tym kwartale?”, „Jakie były koszty w poprzednim raporcie?”, „Gdzie znajdę procedurę bezpieczeństwa?”.
Dzięki RAG odpowiedzi generowane są w oparciu o bazy danych dokumentów i dostarczane jako natychmiastowe odpowiedzi. To redukuje konieczność ręcznego wyszukiwania i daje pracownikom szybki dostęp do istotnych informacji.
2. Wyszukiwanie kontekstowe w dużych repozytoriach
Zamiast klasycznego dopasowania po słowach kluczowych, system analizuje semantykę i zależności w tekście. To oznacza, że nawet jeśli pytania zostały sformułowane inaczej niż w dokumentach, RAG zwróci odpowiednie informacje.
Dzięki temu organizacje zyskują przewagę konkurencyjną, bo pracownicy mogą działać szybciej i pewniej, korzystając z pełnego kontekstu.
3. Streszczanie i wyodrębnianie danych z dokumentów
Raporty finansowe, analizy techniczne czy badania naukowe mogą liczyć setki stron. RAG pozwala na analizowanie treści i generowanie krótkich streszczeń, które pomagają menedżerom i analitykom podejmować decyzje bez konieczności czytania całości. To przykład, jak sztucznej inteligencji używa się do oszczędzania czasu i zwiększania efektywności.
4. Onboarding nowych pracowników
Nowe osoby w organizacji często tracą tygodnie na zrozumienie dokumentacji i procesów. Baza wiedzy oparta o RAG umożliwia szybkie odnajdywanie procedur, regulaminów i instrukcji. W efekcie pracownikom łatwiej przechodzić proces socjalizacji, a firmy skracają czas wdrożenia nowych pracowników.
5. Controlling i finanse
W dziale controllingu RAG automatyzuje wyszukiwanie i przetwarzanie dokumentów: faktur, raportów, umów. Dzięki temu można szybciej przygotować analizy, zidentyfikować anomalie i wesprzeć procesy decyzyjne finansowe. To dowód, że RAG wykorzystuje przetwarzanie języka naturalnego w sposób praktyczny, bezpośrednio powiązany z wynikami biznesowymi.
6. Obsługa klienta
RAG staje się bazą wiedzy, która działa nie tylko dla pracowników, ale też dla klientów. Konsultanci i systemy samoobsługowe dostarczają natychmiastowe odpowiedzi w oparciu o aktualne procedury i dokumenty. To poprawia jakość usług i zwiększa satysfakcję klientów, bo wiedza staje się dostępna w dowolnym miejscu i czasie.
7. Praca z danymi wrażliwymi i poufnymi
W wielu branżach dane, z którymi pracuje się na co dzień, nie mogą być przekazywane do publicznych modeli językowych.
- Kancelarie prawne potrzebują natychmiastowego dostępu do umów, klauzul i orzecznictwa, ale ich treść musi pozostać poufna.
- Laboratoria R&D i zespoły badawczo-rozwojowe pracują na raportach, wynikach eksperymentów i dokumentacji technicznej, której nie zna żaden LLM trenowany na otwartych zbiorach danych.
RAG rozwiązuje ten problem, bo zasila model kontekstem z organizacji, a dane pozostają w obrębie bezpiecznych baz wiedzy firmy. Dzięki temu przedsiębiorstwa mogą korzystać z pełnej mocy sztucznej inteligencji bez narażania własnych tajemnic handlowych i know-how.
Architektura wdrożenia RAG
Zbudowanie prostego PoC w oparciu o open-source to jedno, ale wdrożenie produkcyjnego systemu RAG w przedsiębiorstwie to już zupełnie inna skala wyzwań: bezpieczeństwo, skalowalność, integracje z istniejącymi systemami.
Dlatego Recordya została zaprojektowana jako gotowe narzędzie, które eliminuje konieczność samodzielnego budowania całej infrastruktury.
Główne elementy architektury Recordya
- Lokalne lub chmurowe wdrożenie
- Recordya może działać w pełni on-premise, dostarczona wraz z urządzeniem (tzw. appliance), które można zainstalować w infrastrukturze firmy.
- Alternatywnie system może działać w bezpiecznym środowisku chmurowym.
- W obu przypadkach organizacja zachowuje pełną kontrolę nad zasobami informacyjnymi i prywatnymi dokumentami.
- Obsługa wielu formatów dokumentów
- System automatycznie czyta, analizuje i indeksuje dokumenty w różnych formatach: PDF, Word, Excel, e-maile, pliki tekstowe, a nawet bazy danych.
- Dzięki temu wiedza firmowa zostaje scalona w jedną spójną bazę wiedzy.
- Wektoryzacja i wyszukiwanie kontekstowe
- Dokumenty są dzielone na fragmenty i przekształcane w wektory, które trafiają do bazy danych wektorowej.
- Recordya korzysta z nowoczesnych rozwiązań (np. pgvector, LanceDB), aby umożliwić wyszukiwanie kontekstowe zamiast prostego dopasowania słów kluczowych.
- Integracje z systemami firmowymi
- Recordya posiada bazowe integracje z popularnymi narzędziami do zarządzania dokumentami i procesami (np. SharePoint, Jira, Slack, systemy ERP/CRM).
- To pozwala zasilać model aktualnymi danymi bez konieczności ręcznego importowania plików.
- Bezpieczeństwo i monitoring jakości
- Dane pozostają w obrębie organizacji – niezależnie od tego, czy wdrożenie jest lokalne czy chmurowe.
- Wbudowany monitoring jakości odpowiedzi zapewnia, że pracownikom dostarczane są odpowiednie informacje, a system stale się uczy na podstawie interakcji.
Co to daje w praktyce?
- Zapewnienie bezpieczeństwa danych – dokumenty poufne (umowy, raporty R&D, faktury) nigdy nie opuszczają środowiska firmy.
- Natychmiastowe odpowiedzi dla pracowników – system od razu przeszukuje wszystkie źródła i dostarcza precyzyjne wyniki.
- Oszczędność czasu – automatyzacja przetwarzania dokumentów eliminuje konieczność ręcznego wyszukiwania i analizowania treści.
- Skalowalność – architektura pozwala rozwijać system wraz z potrzebami organizacji.
Wyzwania we wdrożeniach RAG
Choć idea Retrieval-Augmented Generation wydaje się prosta, wdrożenie jej w przedsiębiorstwie napotyka kilka poważnych wyzwań technologicznych:
1. Bezpieczeństwo danych
Firmy pracują na poufnych dokumentach – od umów prawnych, przez raporty R&D, aż po faktury i analizy finansowe. W klasycznych podejściach ryzyko wycieku danych do chmury publicznej jest realne.
Recordya rozwiązuje ten problem, oferując możliwość pełnego wdrożenia on-premise lub w zamkniętym środowisku chmurowym, gdzie zasoby informacyjne nigdy nie opuszczają infrastruktury organizacji.
2. Skalowalność i wydajność
Proste PoC zwykle działają na ograniczonej próbce dokumentów. W produkcji trzeba jednak obsłużyć:
- tysiące plików w różnych formatach,
- setki zapytań użytkowników jednocześnie,
- konieczność stałej aktualizacji bazy wiedzy.
Recordya jest projektowana jako system klasy enterprise, który skaluje się wraz z rosnącymi potrzebami organizacji.
3. Koszty obliczeniowe
RAG łączy uczenie maszynowe z intensywnym wyszukiwaniem wektorowym. Niewłaściwie zaprojektowana architektura szybko generuje wysokie koszty obliczeń i przechowywania danych.
Recordya optymalizuje procesy: stosuje inteligentne dzielenie tekstu, cache’owanie wyników i nowoczesne bazy danych wektorowych, co redukuje obciążenia infrastruktury i obniża koszty.
4. Różnorodność formatów danych
Firmy korzystają z szerokiego wachlarza źródeł – PDF-ów, arkuszy Excel, e-maili, baz danych, systemów ERP i CRM. Zbudowanie własnego parsera dla wszystkich tych formatów jest czasochłonne i wymaga wysokich kompetencji technicznych.
Recordya od razu czyta, analizuje i indeksuje dokumenty w wielu formatach, łącząc je w jedną spójną bazę wiedzy.
Przyszłość RAG w praktyce
Retrieval-Augmented Generation to nie chwilowy trend, lecz trwały kierunek rozwoju sztucznej inteligencji w zarządzaniu wiedzą. Firmy już dziś potrzebują narzędzi, które:
- zapewniają bezpieczeństwo danych,
- wspierają procesy decyzyjne,
- automatyzują przetwarzanie dokumentów,
- i działają w oparciu o własne zasoby informacyjne.
Co będzie kluczowe w najbliższych latach?
- Integracja z systemami biznesowymi
RAG nie będzie już osobną warstwą, lecz stanie się częścią codziennego ekosystemu firm. Recordya już teraz oferuje integracje z popularnymi narzędziami do zarządzania dokumentami, ERP czy CRM. - Monitoring jakości odpowiedzi
Coraz ważniejsze staje się zapewnienie, że odpowiedzi AI są trafne, spójne i audytowalne. Recordya ma wbudowany mechanizm monitorowania jakości i historii zapytań użytkowników, co umożliwia kontrolę i ciągłe doskonalenie systemu. - Systemy agentowe oparte na RAG
Kolejnym krokiem będzie automatyzacja procesów biznesowych – np. agent finansowy, który sam przygotuje raport na podstawie faktur, albo agent HR wspierający onboarding nowych pracowników. Recordya to fundament, który umożliwia rozwijanie takich zastosowań. - Bezpieczne wdrożenia lokalne (on-premise)
W dobie rosnących regulacji i wymagań compliance, możliwość korzystania z lokalnych baz danych i prywatnych repozytoriów dokumentów będzie coraz ważniejsza. Recordya od początku została zaprojektowana z myślą o takim scenariuszu. - Wielojęzyczność i lokalna specyfika
RAG w językach fleksyjnych (jak polski) to wyzwanie, które będzie coraz częściej podnoszone. Recordya już dziś dostarcza RAG po polsku, działający również z dokumentami w innych językach, co odpowiada na realne potrzeby globalnych zespołów.
Jak wdrożyć produkcyjny system RAG w twojej firmie?
Wiele organizacji eksperymentuje z własnymi PoC opartymi o RAG, ale tylko nieliczne potrafią przejść od prototypu do stabilnego, bezpiecznego rozwiązania działającego na dużą skalę. To właśnie ten moment, w którym Recordya robi różnicę.
Dlaczego Recordya?
- Gotowe narzędzie – nie musisz budować infrastruktury od zera.
- Bezpieczne wdrożenie on-premise lub w chmurze – pełna kontrola nad prywatnymi danymi i dokumentami.
- Obsługa wielu formatów danych – PDF, Word, Excel, e-maile, bazy danych i systemy ERP/CRM.
- Integracje z twoimi systemami – Recordya działa w ekosystemie, który już masz.
- RAG po polsku – dopasowane do specyfiki języka i dokumentów w twojej firmie, a jednocześnie obsługujące wiele języków.
- Skalowalność klasy enterprise – niezależnie od tego, czy masz setki, czy miliony dokumentów.
Co zyskuje twoje przedsiębiorstwo?
- Baza wiedzy, która odpowiada na zapytania użytkowników i wspiera wszystkie procesy decyzyjne.
- Automatyzację przetwarzania dokumentów, co pozwala pracownikom skupić się na rozwiązywaniu problemów zamiast na szukaniu plików.
- Przewagę konkurencyjną, bo wykorzystujesz własny kapitał intelektualny szybciej i efektywniej niż inni.
- Natychmiastowe odpowiedzi dostępne dla pracowników i klientów w dowolnym miejscu.
Zacznij już dziś
Jeśli chcesz, aby sztuczna inteligencja realnie wspierała zarządzanie wiedzą w twojej firmie, postaw na rozwiązanie, które jest:
- sprawdzone,
- bezpieczne,
- i gotowe do użycia od razu.
👉 Skontaktuj się z nami i umów demo Recordya – zobacz, jak łatwo twoja firma może zyskać własną bazę wiedzy nowej generacji.



